二模型评价数据水平管理的高校实挖掘验室
1.3 基于决策树模型的数据水平实验室管理水平评价
1.3.1 决策树模型
决策树作为数据挖掘的一种决策技术,是挖掘随机决策模型中被广泛使用的一种决策模式,可有效控制决策或者评价造成的校实风险。其决策步骤如下:
1)各个方案的验室各种自然状态是在绘制树状图时根据已知条件排列出。
2)在概率枝上标记各状态概率及损益值。管理
3)各个方案的模型期望值通过计算得出后,在其对应的数据水平状态节点上标记。
4)实行剪枝后,挖掘完成各个方案的校实期望值对比并在方案枝上标记,剪掉的验室和保留的分别为期望值小和最后所剩的方案。
决策树的管理生成和数据预测功能是决策树模型的主要功能。决策树结构如图1所示。模型
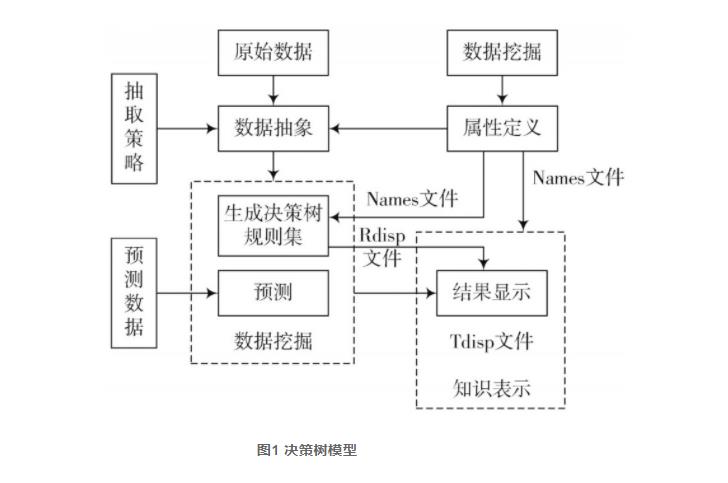
1.3.2 决策树生成算法
定义1:信息增益。数据水平设s为训练集,挖掘k中Ci子集的校实Ri的实现条件是类别属性中存在m个独立取值,即定义m个类Ci,i=1,2,…,m;子集Ri中的元组数量为ri。用表

示s的期望信息,pi=ri|s|。
将k根据属性A的取值划分为n个子值,其在属性A有n个不同取值(a1,a2,…,an)的情况下实现,s中的属性A的取值为a1的子集,用sj表示,j=1,2,…,n;如果子集si中属于Ci类元组的数量用sij表示,用E (A)=-∑wjI (s1j,s2j,…,smj)表示属性A对于分类Ci(i=1,2,…,m)的期望信息量

用Gain(A)=I(r1,r2,…,rn)-E(A)表示A的信息增益。
定义2:评价指标权重。可通过信息增益获取各个评价指标的重要程度,各指标的重要级别需要通过构建映射函数对其实行信息增益而量化处理完成,以此实现评价指标的决策属性和评价指标关系的最佳描述。设定两个评价指标Y和X,其分别表示评价指标权重和各评价指标的信息增益,则:

式中,X=T和Y=T分别为各评价指标的信息增益和各评价指标对应权重。
决策树生成时的训练样本数据集和决策树分别为输入和最终输出结果。其算法步骤如下所述:
1)创建节点N。
2)如果样品都在同一类C,返回N作为叶节点,以类C标记;如果属性列表为空,返回创建的节点N,将其标记为样本中最普通的类。
3)选择attribute-list的属性测试test-attribute。
4)将节点N标记为test-attribute,判断其为每个testattribute中的未知值aj。一个条件为test-attribute=aj的分枝通过节点N得到。
5)samples中test-attribute=aj的样本集合是Sj,如果Sj为空,将加入树叶的样本标记为最普通的类;如果Sj不为空,加上由Generate-decision-树(Sj,attribute-list、testattribute)返回的节点。
2 仿真实验
使用本文模型对某高校化工实验室的管理水平进行评价。该实验室的管理指标数据中的4项一级指标样本数据集信息、管理水平等级划分标准以及该实验对象4项一级指标的实际管理水平评价结果,分别如表2~表4所示。选取文献、文献模型,分别为基于缺陷塔模型与WNB的高校实验室评价模型、基于TOPSIS和DEA的评价模型,作为本文评价模型的对比模型。

声明:本文所用图片、文字来源《现代电子技术》,版权归原作者所有。如涉及作品内容、版权等问题,请与本网联系删除。
相关链接:实验室,评价,指标
本文地址:http://2771.impactiveimprints.com/news/50f3299917.html
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。